背景
上个月,在跟北京同事的技术交流中,聊到了MySQL的两阶段提交。原本以为,这块的MySQL源码翻过两遍,基本能够理解其逻辑并自圆其说。遗憾的是,还是没讲清楚,虽然主要是还是当时状态不好。但网上搜索相关的资料,要么就是不全,没有专门的文章去分析;要么就是理论太落后,几乎有基于MySQL 5.6的源码分析得出的理论。然而,现在8.0都开始在生产环境,摩拳擦掌,跃跃欲试。因而,想着着手梳理5.7的代码,并展望8.0的优化。
思考
1、事务在Redo日志与Binlog日志中的提交顺序是否总是一致?它们是通过什么来保证的?
2、在组提交背景下,变量last_committed与sequence_number是如何实现并行复制的?
3、事务在GTID与sequence_number中的顺序是否总是一致?它们分别是在哪个阶段产生与持久化的?
4、在两阶段提交方面,相比MySQL 5.7,MySQL 8.0有哪些改进以及优化?
5、在MySQL 5.7中,GTID是怎么持久化的?什么时候会更新mysql.gtid_executed表?MySQL崩溃恢复后又是如何保证GTID不丢的?
6、你能描述MySQL 8.0克隆插件的原理吗?为什么会引入GTID持久化机制?为什么GTID持久化不依赖克隆的存在而存在?即,它解决了什么问题?
理论基础
维基百科搜索两阶段提交,可以找到官方定义
二阶段提交协调者参与者参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈情报决定各参与者是否要提交操作还是中止操作
你怎么理解两阶段提交?为什么要分两阶段?一阶段提交不就完事?个人理解:MySQL两阶段提交是以事务协调器(或者虚函数)作为协调者,以Binlog与InnoDB为参与者,根据prepare与commit顺序,依次调用Binlog层实际处理逻辑与InnoDB层实际处理逻辑。本质为让尽可能多的操作并行执行,而并行执行的这块操作放在准备阶段。由于数据库的日志先写原则,这意味着,在prepare阶段会让日志先落盘,在commit阶段再进行真正的提交,以达到更好并发的目的。
源码分析
对MySQL源码不感兴趣可直接跳过本块内容。
- prepare阶段
以函数MYSQL_BIN_LOG::prepare
prepare阶段会分别依次阻塞性调用binlog_prepare与innobase_xa_prepare函数:在5.6.51中可以看到binlog_prepare是个空函数,什么也不做。而5.7.26可以看到,对于事务型型语句,会在这时获取last_committed值,即随着组提交的引入而发生了变化。继续看8.0.18,并未发生新的变化。另外,可以看到,从5.7.26开始,设置了持久化属性为HA_IGNORE_DURABILITY,即在prepare阶段不再对Redo日志刷盘;而对于InnoDB层的prepare,可以看到,
- 5.7.26开始关闭临时表空间的Redo日志,因为它不需要崩溃恢复
- 8.0.18后由于克隆插件的引入而引入GTID持久化机制
- 从5.7.26开始,RC隔离级别及以下,会释放GAP锁
- 从5.7.26开始,因使用HA_IGNORE_DURABILITY属性,在prepare阶段不再处理由innodb_flush_log_at_trx_commit参数控制的Redo日志的刷盘
- 8.0.18后由于原子DDL的引入,而在prepare阶段会进行Redo刷盘,而不受innodb_flush_log_at_trx_commit参数控制
- commit阶段
以函数MYSQL_BIN_LOG::commit
- 从5.6.51开始就已经引入了三队列(即组提交),flush队列、sync队列以及commit队列,为了对两阶段提交进行优化,主要解决的是binlog日志组提交的问题。
组提交引入的worklog:
2. 从5.7.26开始,关闭了prepare阶段的Redo日志刷盘,把它放到了flush队列中处理,这样的话,就解决了Redo日志的组提交。
3. 从5.7.26开始,加入了has_commit_order_manager函数判断逻辑,即有了顺序提交功能(对应参数slave-preserve-commit-order),这样就保证了从库一直处于一个一致的状态。
4. 从5.7.26开始,可控制组提交的并发程度。具体通过参数binlog_group_commit_sync_no_delay_count和binlog_group_commit_sync_delay在sync阶段的最开始实现等待。
版本演进
- MySQL 5.5.62
为了梳理MySQL两阶段提交的进化,首先从MySQL 5.5.62(最新的5.5版本)开始。5.5之前的,这里,不再考虑。原理如下所示:
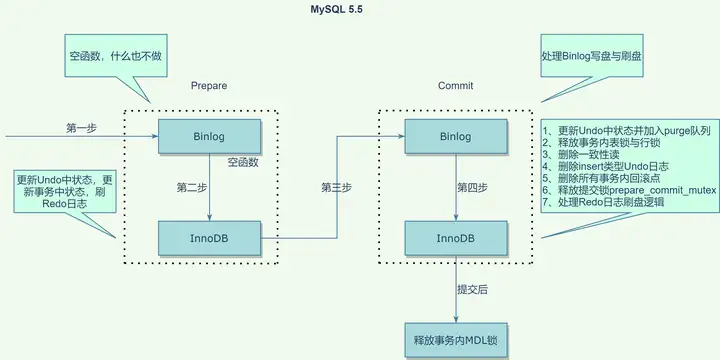
说明:提交分为两阶段,左边为prepare阶段,右边为commit阶段;每个阶段都是通过一个回调函数,依次调用到Binlog层与InnoDB层;prepare阶段在Binlog层什么都不需要做,而在InnoDB层更新下相关的状态,进行Redo日志的刷盘处理;commit阶段才进行真正的操作,即Binlog的刷盘与InnoDB层的提交。
互斥锁prepare_commit_mutex在InnoDB的prepare阶段最后获取,在commit阶段处理Redo日志刷盘前释放,这样就保证了同一个时刻只有一个线程在处理Binlog写盘与InnoDB层提交,保证了InnoDB层提交与Binlog的顺序一致性;
官方设计思路:
可以看到Redo日志有两次刷盘,一次在prepare(1-b)阶段,一个次在commit(3-c)阶段
1. Prepare Innodb:
a) Write prepare record to Innodb's log buffer
b) Sync log file to disk
c) Take prepare_commit_mutex
2. "Prepare" binary log:
a) Write transaction to binary log
b) Sync binary log based on sync_binlog
3. Commit Innodb:
a) Write commit record to log
b) Release prepare_commit_mutex
c) Sync log file to disk
d) Innodb locks are released
4. "Commit" binary log:
a) Nothing necessary to do here.2. MySQL 5.6.51
有了以上的基础,我们再来探索下一个版本,即MySQL 5.6.51(最新的5.6版本)的进化。梳理代码,变化如下:
- 去掉了互斥锁prepare_commit_mutex,而代之以队列保证InnoDB层与Binlog的顺序一致性
- 把原来的commit阶段拆成了三阶段,即FLUSH阶段、SYNC阶段与COMMIT阶段,分别会获取互斥锁LOCK_log、LOCK_sync与LOCK_commit
- 对于在COMMIT队列中的每个线程来说,与前一个大版本类似,在InnoDB层的提交最后处理Redo日志刷盘时,增加了属性HA_IGNORE_DURABILITY来跳过处理
- 引入了GTID,在FLUSH队列处理中,Binlog线程缓存写入Binlog文件缓存之前通过一个全局变量生成
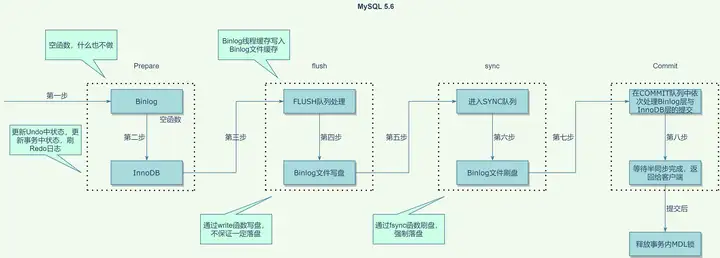
flush队列处理阶段,通过参数binlog_max_flush_queue_time调大等待时间以减少flush队列的大小以降低flush的队列处理的并发程度。
总的来说,从此版本开始,因引入了组提交而优化了Binlog刷盘的性能问题。而Redo日志的提交,仍未变化。另外,通过把COMMIT阶段拆成了三阶段,每个阶段独立获取锁,即把一个大锁拆成了三把小锁,使Binlog刷盘部分不持有提交阶段的锁,进而提高了并发。以组为单位队列又保证了提交的顺序性。
互斥锁LOCK_log、LOCK_sync与LOCK_commit有什么用?解决了什么问题?个人理解,互斥锁,解决的是,同一时刻每个阶段只有一个队列的问题,即队列与队列之间是串行的。而队列内部的顺序性,又保证了加入队列的事务是串行的。
想想,Binlog刷盘会经历那几个阶段?binlog_cache_size是约束哪个缓存的?这里不再赘叙,有兴趣的同学可自行搜索。
3. MySQL 5.7.26
接着,我们再来探索下一个版本,即MySQL 5.7.26(当前最新的5.7版本)的进化,梳理代码,变化如下:
- 上一个版本虽然引入了Binlog的组提交,但仍然没有解决从库的并行回放问题(虽然已经引入了按照库级别的并行回放),在该版本中随即引入了两个变量last_committed(记录每组的leader序列号,即每组事务的最小序列号)与sequence_number(记录每个事务的序列号)来解决从库的并行回放问题
- 在InnoDB的prepare阶段修改Undo状态的时候,会对临时表空间的Undo与系统表空间(或者Undo表空间)分别处理,临时表空间处理的时候会进行标记,让它不写Redo日志
- 在InnoDB的prepare阶段的已提交读隔离级别以下会释放GAP锁
- 通过HA_REGULAR_DURABILITY属性取消了InnoDB的prepare阶段Redo日志刷盘,而把它放在了FLUSH阶段,进而实现了Redo的组提交
- 引入了并行复制worker线程的顺序提交,埋点在FLUSH队列处理前,因为Redo的刷盘已经放在了FLUSH阶段,即不影响Redo与Binlog的顺序
- 在FLUSH阶段,引入了Redo日志的处理逻辑,但仅在innodb_flush_log_at_trx_commit为1时生效,为0时跳过。之后,按队列依次生成GTID,生成之后再去处理Binlog线程缓存写入Binlog文件缓存,这样就便于了GTID的集中生成
- 在FLUSH阶段,在Binlog线程缓存写Binlog文件缓存之前,即写入GTID之前,会先获取全局的sequence_number值
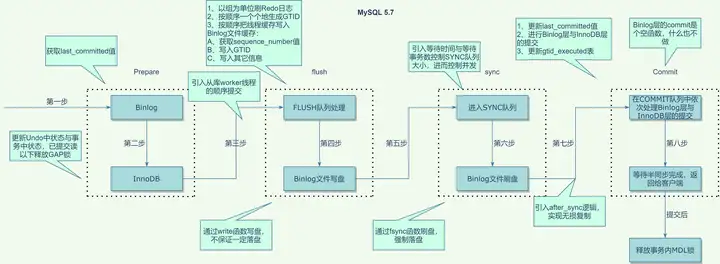
想想,Binlog中的Xid是什么?它是什么时候生成的?在崩溃恢复的时候,有什么作用?内核月报有相关的文章说明(内核月报:MySQL · 引擎特性 · InnoDB 崩溃恢复过程),不过需要注意的是,没有说明是从Undo中找出prepare状态的Xid。这点,看过内核月报的同学,有问过。
4. MySQL 8.0.18
最后,我们探索下最后的大版本,即MySQL 8.0.18(当前最新的8.0版本)的进化。梳理代码,可以发现,除了引入GTID持久化机制,基本没啥变化。那,为什么要引入GTID持久化?经过搜索代码中的一个关键类Clone_persist_gtid可以找到相关的worklog(WL#9211: InnoDB: Clone Replication Coordinates)。整理下它的大致意思:
- 事务提交时,会把GTID也写入Undo中,因为对Undo本身的修改也会写Redo,这样就保证了GTID的持久化;同时也会把GTID写入一个链表
- 引入一个后台线程clone_gtid_thread用于异步把链表中的GTID写入mysql.gtid_executed表,每隔1秒或者1024个事务写一次
- purge线程在删除Undo前会检查当前GTID是否存在于GTID链表,如果存在则不能删除,直到它被写入mysql.gtid_executed表中
看了半天,总算明白了它的意图。克隆插件的原理,这里不必细说(内核月报:MySQL · 引擎特性 · clone_plugin)。假设,现在已经做好了一个一致性的快照,按照原来手工搭建从库的方式,你还得找到备份文件中Binlog的点位信息或者GTID信息,否则无法连接主库进行Binlog复制。因为本身该类为克隆插件中一个大类的子类,本以为是安装了克隆插件执行克隆操作的时候,才会用到该逻辑。但调试后发现,正常逻辑,也会走以上流程。不难想到,意图明显,弱化了Binlog的作用。想想,Xtrabackup用来做一致性备份的时候,为什么需要flush logs操作?个人结论:用来在线获取一致性GTID,使阻塞时间小于1秒;GTID不再依赖Binlog持久化,进一步弱化Binlog作用。
在MySQL 5.7中,mysql.gtid_executed表只会在Binlog切换的时候更新一次,当然你可以手工去执行“flush logs
变化如下:
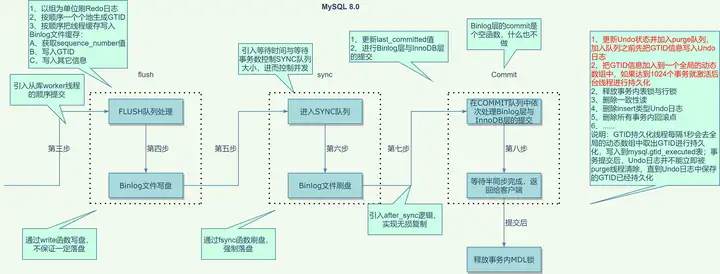
所以,在两阶段提交方面,相比MySQL 5.7,MySQL 8.0有哪些改进和优化?个人结论:没有优化。
总结
相信认真读到这里的同学,基本对MySQL两阶段提交有了一个深入的了解,对于思考环节中的那六个问题,应该有了自己的答案了吧。